Artificial Intelligence, zBlog
Open Source AI Models for Enterprise — The Complete 2026 Decision Guide
Team Trantor | Updated: June 4, 2026

Open source AI models are, technically, free. The weights are downloadable. The license says commercial use is permitted. You can spin one up on your own infrastructure tonight.
So why are so many enterprise AI programs running over budget in year one?
Because “free” is the acquisition cost, not the total cost. There is the GPU infrastructure. The DevOps hours. The security audit. The fine-tuning compute. The monitoring infrastructure. The engineering time spent chasing hallucinations that the proprietary model would have caught. Open source AI models are a powerful choice for the right organization deploying them in the right way. They are an expensive mistake for organizations that confuse “no API bill” with “no cost.”
This guide gives you the real picture — benchmarks, licensing fine print, TCO math, and a model-by-model breakdown covering every major open source family as of May 2026. Read the whole thing if you are making a strategic decision. Jump to the model cards if you already know what use case you are solving.
The Gap Between Open Source and Proprietary AI Effectively Closed in 2025
Something remarkable happened in 2025 that most enterprise AI strategies have not yet caught up with: the performance gap between open source and proprietary large language models effectively vanished.
The MMLU benchmark gap — the most widely used measure of general intelligence across AI models — narrowed from 17.5 percentage points to just 0.3 percentage points in a single year. What was once a multi-year frontier gap is now measured in weeks. Llama 4 Maverick outperforms GPT-4o on major benchmarks at $0.30 per million tokens. DeepSeek R1 delivers GPT-4-class reasoning for $0.55 per million input tokens — 27 times cheaper than Claude Opus. Qwen 3.5 from Alibaba quietly matches GPT-5.4 and Claude 4.6 Opus on several benchmarks, with download numbers that tell the real adoption story.
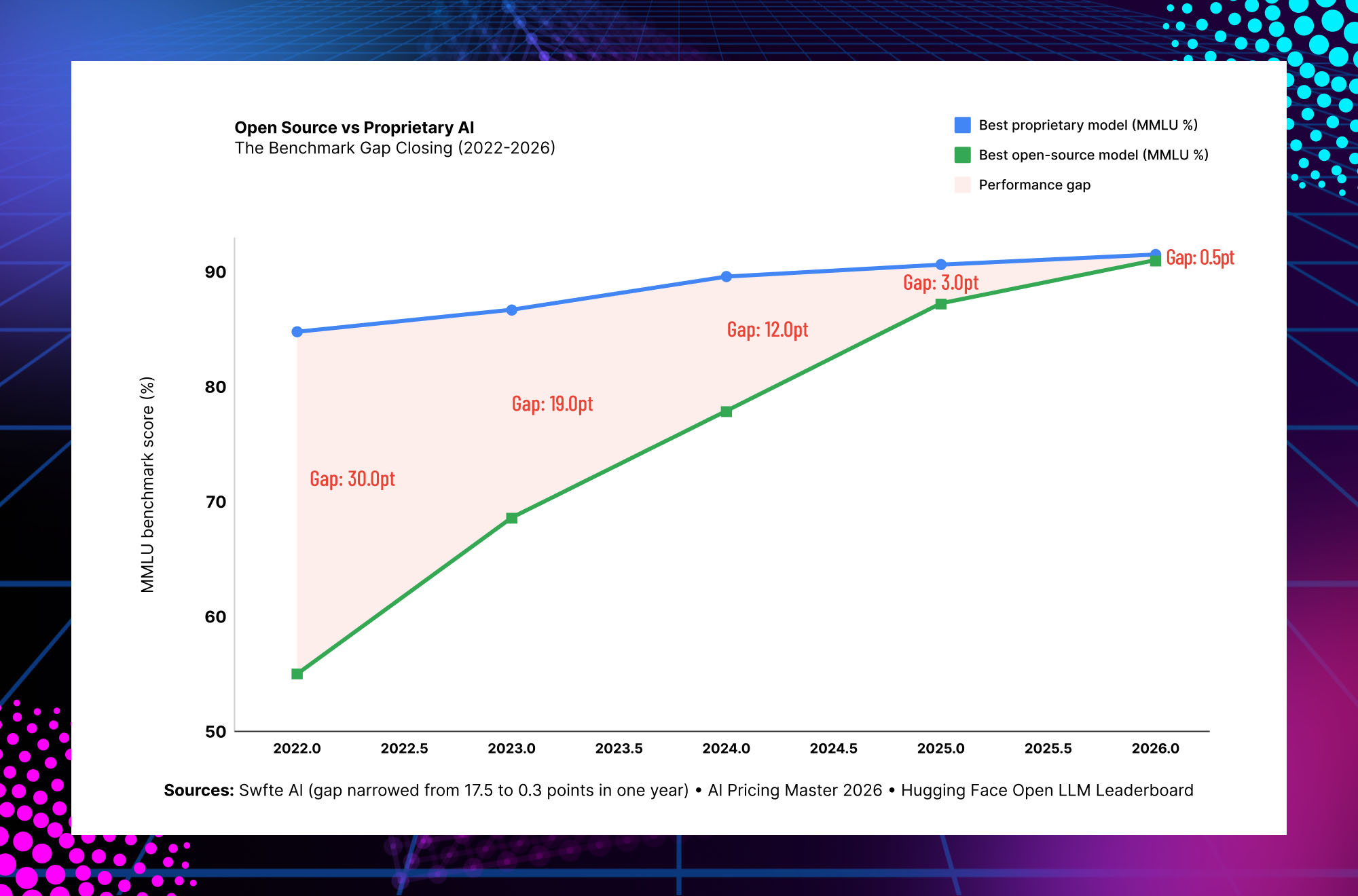
For enterprise AI teams, this changes the decision calculus entirely. The question is no longer “can open source models perform well enough?” For 80–90% of real-world use cases, they can. The question is “what is the right deployment architecture for our specific workflow, compliance requirements, and cost structure?” That is a much more interesting question — and this guide answers it.
KEY INSIGHT:
Enterprises are now running open models for internal workloads and reserving proprietary API calls only for high-stakes, external-facing tasks. This hybrid pattern achieves 60–83% cost reductions without sacrificing quality on the tasks that matter most.
First: The Most Important Distinction Nobody Explains Properly
Before picking a model, you need to understand a terminology problem that is costing enterprises real money and, in some cases, creating legal exposure.
Three terms get used interchangeably in the press and on vendor sites. They mean very different things:
Open Source: Model weights + training code + training data documentation, all publicly available under an OSI-approved license. Very few major models actually meet this standard.
Open Weight: The model weights are downloadable. Training code and data may not be public. This is where most major models — Llama, Qwen, Gemma, DeepSeek, Kimi, GLM — actually sit. You can run them. You cannot reproduce the training.
Commercial Open Weight: Weights are downloadable and commercial use is explicitly permitted — but read the license. Some have revenue caps (Llama: restricted for organizations over 700 million monthly active users). Some have geographic restrictions. Some prohibit using the weights to train other models.
LICENSE TRAP:
The phrase “open source” on a model card does not mean Apache 2.0 or MIT. It may mean a custom license with user caps, geography restrictions, or prohibitions on derivative model training. If you are building a product on any of these models, your legal team needs to read the full license before your engineering team writes a line of code. The table below shows which models are genuinely safe for commercial deployment without restrictions.
| Model | License | Commercial? | Modify? | Revenue cap? | Safe for enterprise? |
|---|---|---|---|---|---|
| Qwen 3.5 (≤32B) | Apache 2.0 | ✓ Yes | ✓ Yes | ✗ None | ✓ YES |
| DeepSeek R1 / V4 | MIT | ✓ Yes | ✓ Yes | ✗ None | ✓ YES* |
| Mistral Large 3 | Apache 2.0 | ✓ Yes | ✓ Yes | ✗ None | ✓ YES |
| Gemma 4 | Apache 2.0 | ✓ Yes | ✓ Yes | ✗ None | ✓ YES |
| Llama 4 | Meta Custom | ✓ Yes | ✓ Yes | ⚠ 700M MAU | ⚠ CHECK |
| GLM-5 | MIT | ✓ Yes | ✓ Yes | ✗ None | ✓ YES* |
| Phi-4 | MIT | ✓ Yes | ✓ Yes | ✗ None | ✓ YES |
* Verify data residency and export compliance requirements before enterprise deployment.
If license flexibility is your top priority, Apache 2.0 and MIT are the cleanest options — Qwen 3/3.5 (≤32B), Mistral Large 3, Gemma 4, and Phi-4 all ship under these terms. No usage caps. No royalties. No geographic restrictions. You can fine-tune, modify, and commercially deploy without restriction.
The Real Cost Picture — API Pricing vs Self-Hosting TCO
“Open source is free” is the most expensive misconception in enterprise AI in 2026. Here is the actual cost structure, because this is where most organizations go wrong.
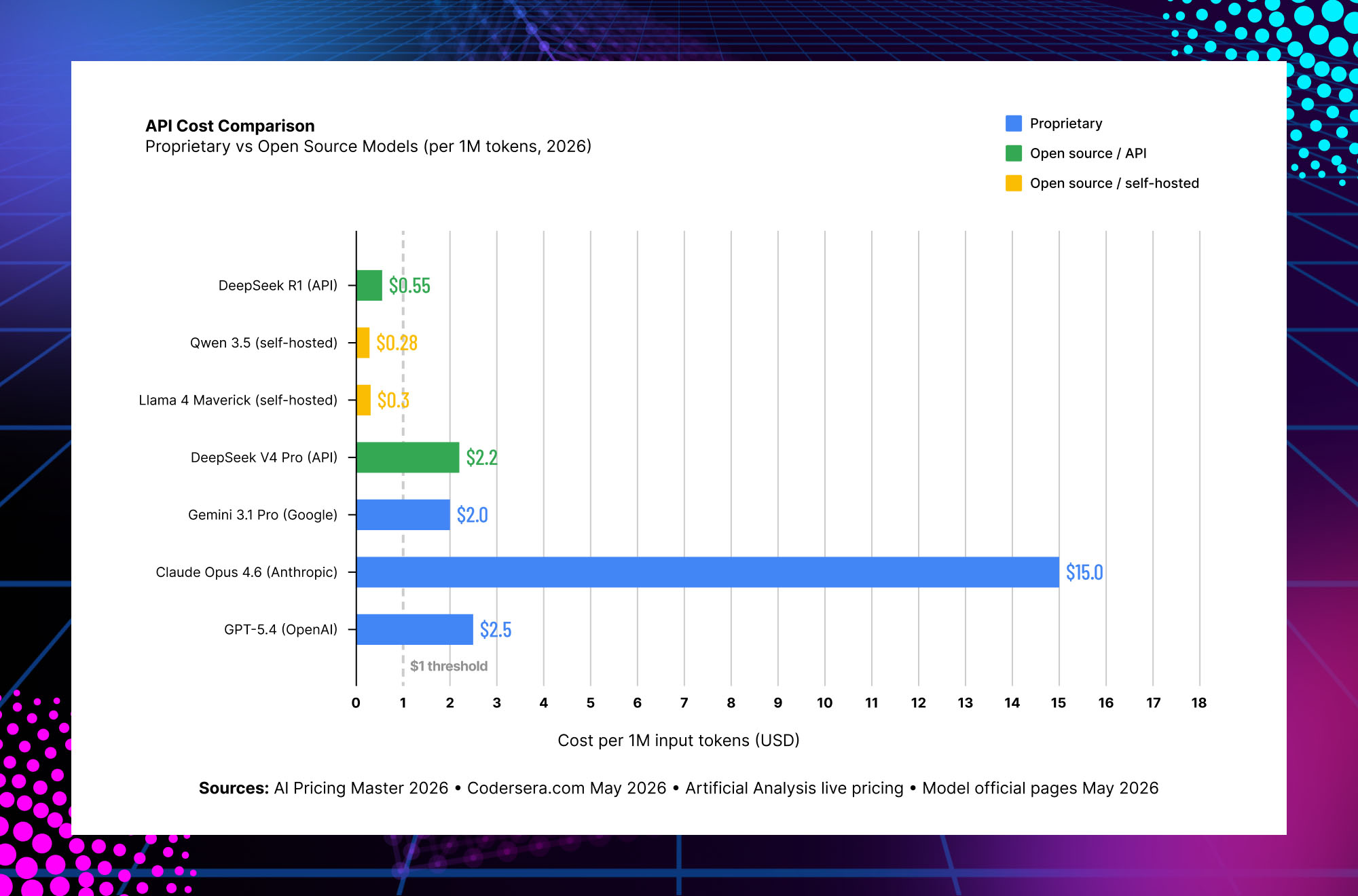
Option A: Use Open Source Models Via Third-Party API
Providers like Together.ai, Fireworks.ai, and Groq host open source models and charge per token. DeepSeek V4 Pro via API is ~$2.20/M tokens. Llama 4 Maverick via Groq is ~$0.30/M tokens. This is significantly cheaper than proprietary APIs ($2.50–15/M for GPT-5.4 or Claude Opus 4.6), and you get the cost benefits without the infrastructure burden. The tradeoff: your data still passes through a third party’s servers, which may not satisfy HIPAA, SOC 2, or GDPR requirements depending on where the servers are located.
Option B: Self-Host on Your Own Infrastructure
This is the “truly free” path — but only at sufficient scale. Self-hosting breaks even at approximately 2 million tokens daily when you account for GPU costs, DevOps overhead, monitoring, and ongoing maintenance. Below that threshold, proprietary APIs or third-party hosted open models typically win on total cost of ownership once you factor in engineering time.
The math: an H100 GPU costs $2–4/hour on major cloud providers, or $1.85–2.20/hour on AMD MI300X. At 720 hours per month, your base GPU cost is $1,440–2,880 before DevOps, storage, monitoring, and engineering overhead. For a 7B model handling internal search queries at low-to-medium volume, you are paying more per query than a proprietary API. For a 70B model handling 10 million tokens per day of document processing, self-hosting can save $50,000+ per month versus GPT-4 pricing.
Option C: The Hybrid Architecture (What Most Mature Enterprises Use)
NVIDIA’s CEO stated it clearly: “Proprietary versus open is not a thing. It’s proprietary AND open.” The practical enterprise architecture in 2026 separates workloads by consequence and volume. High-consequence, external-facing tasks (customer communications, executive decision support, legal document analysis) go to proprietary frontier models. High-volume, internal tasks (knowledge search, document summarization, internal chatbots, code review) go to open source models — either self-hosted or via API. Companies implementing this hybrid routing are achieving 60–83% cost reductions without quality compromise on the tasks that actually matter to business outcomes.
The Data Sovereignty Question Every Enterprise Needs to Answer
In 2025, Chinese AI organizations steered heavily into open source. The number of competitive Chinese organizations releasing models on Hugging Face skyrocketed. Baidu went from zero releases on the Hub in 2024 to over 100 in 2025. ByteDance and Tencent each increased releases eight to nine times. Chinese open-source AI models jumped from 1.2% of global usage in late 2024 to nearly 30% by end of 2025.
DeepSeek, Qwen, Kimi, and GLM are among the highest-performing models by benchmark. They are also models developed by organizations subject to Chinese data laws — including the National Intelligence Law, which requires organizations to cooperate with Chinese intelligence operations when requested.
DATA SOVEREIGNTY RISK:
When DeepSeek or Qwen models are used via their official cloud APIs, user data routes through mainland China — up to 100,000 words per request. This is a material risk for enterprises in defense, government, healthcare, financial services, and any organization handling personal data subject to GDPR. However: the model weights themselves have no networking capability. Running DeepSeek or Qwen weights on your own infrastructure, in your own cloud region, means your data never leaves your servers. The risk is the API, not the weights. Know which deployment mode you are using.
The practical guidance: for regulated industries or organizations with government clients, either run Chinese model weights on your own EU/US infrastructure with a model-swappable architecture, or use European models (Mistral) or US models (Llama, Gemma, Phi) for sensitive workloads. For internal, non-sensitive workloads where cost efficiency is the priority and data never touches the Chinese cloud APIs, DeepSeek and Qwen weights on your own infrastructure are genuinely strong options.
The 8 Best Open Source AI Models for Enterprise in 2026
Every model below has been evaluated for enterprise deployment — not just benchmark scores, but licensing, hardware requirements, community support, and real production viability. Models are grouped by use case fit, not benchmark rank.
How the Model Families Compare — 6 Enterprise Dimensions
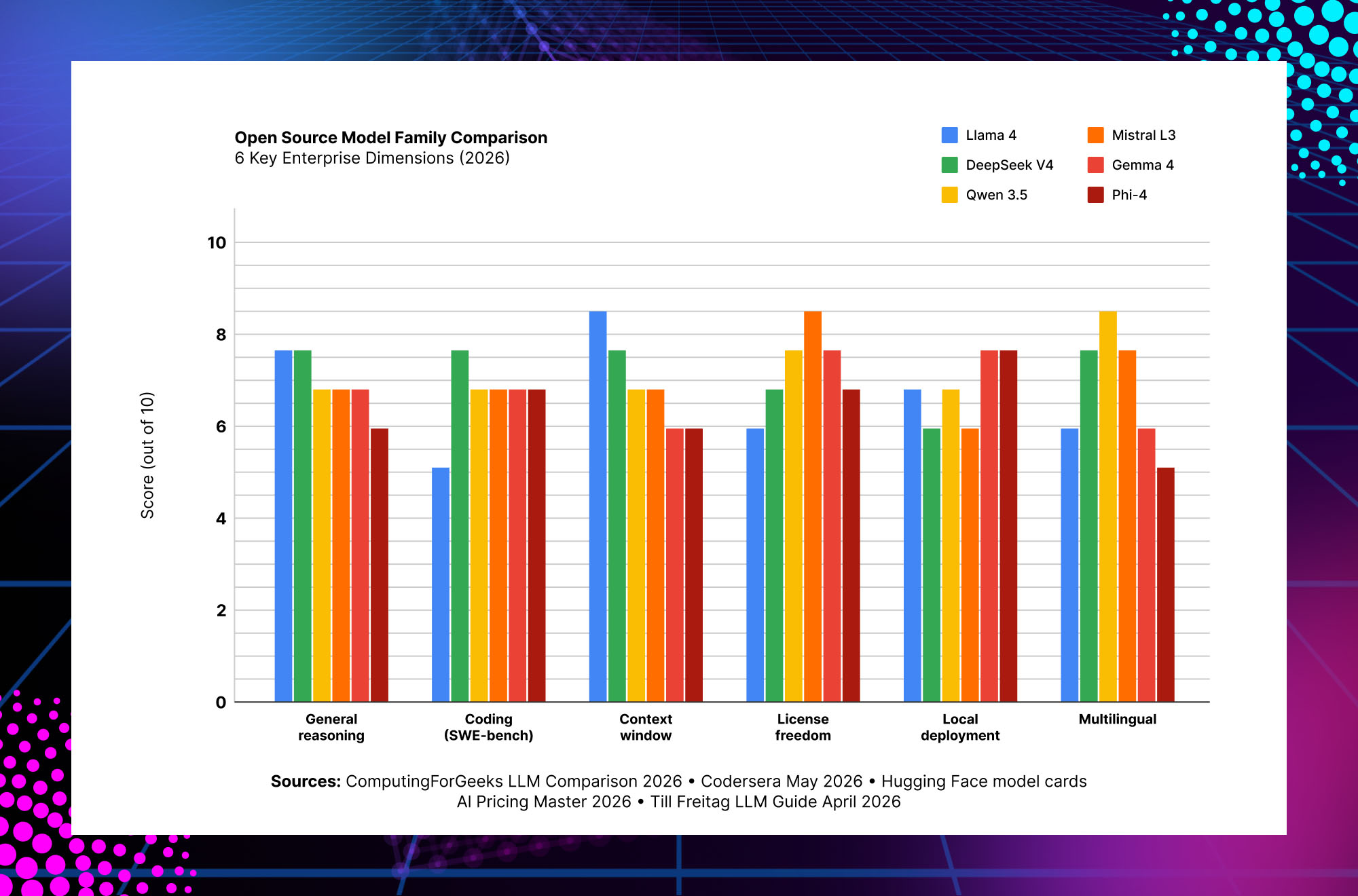
The chart above scores each model family on six dimensions that matter for enterprise deployment: general reasoning (MMLU-class benchmarks), coding ability (SWE-bench Verified), context window (raw token capacity), license freedom (permissiveness for commercial use), local deployment practicality (hardware requirements vs performance), and multilingual coverage.
The key enterprise takeaway: no single model dominates every dimension. Qwen 3.5 leads on multilingual and license freedom. DeepSeek V4 leads on coding. Llama 4 leads on context window. Mistral Large 3 leads on license freedom plus data sovereignty. Gemma 4 leads on local deployment practicality. Building the right stack means understanding which dimensions matter most for your specific workloads — and accepting that a hybrid of two or three models likely outperforms any single model choice.
Use Case → Model Decision Matrix
Stop searching for “the best open source model.” The right question is always “the best model for this specific use case, compliance requirement, and deployment context.”
| Use Case | Recommended Model | Deployment Pattern |
|---|---|---|
| High-volume internal search / document summarization | DeepSeek V4 Flash or Qwen 3.5 30B | Open-weight API or self-hosted |
| Customer-facing outputs (tone, accuracy critical) |
Claude Opus 4.6 / GPT-5.4 | Proprietary API |
| Code review / coding agent (self-hosted, air-gapped) |
Devstral / Kimi K2.6 / GLM-5.1 | Self-hosted on enterprise GPU |
| Regulated industry (HIPAA/GDPR, no data leaving) |
Mistral Large 3 / Gemma 4 | On-prem deployment, EU/US infra |
| Multilingual / global apps (200+ languages) |
Qwen 3.5 (Apache 2.0) | API or self-hosted |
Based on TIMEWELL/NVIDIA enterprise framework · Codersera 2026 · AI Pricing Master enterprise routing guide
Based on TIMEWELL/NVIDIA enterprise framework · Codersera 2026 · AI Pricing Master enterprise routing guide
The three-tier enterprise framework that practitioners in the field recommend: at the top, proprietary frontier models (Claude Opus, GPT-5.4, Gemini 3.1 Pro) for customer-facing work and top-tier reasoning. In the middle, open-weight large models (Mistral Large 3, Qwen 3.5, Llama 4, DeepSeek V4 — those satisfying your regulatory requirements) on-premises or in a domestic cloud for fast, cheap internal processing. At the bottom, small distilled models (Phi-4, Gemma 4, Qwen3-7B) for edge inference, personal productivity tools, and low-latency applications.
Hardware Requirements — What You Actually Need to Self-Host
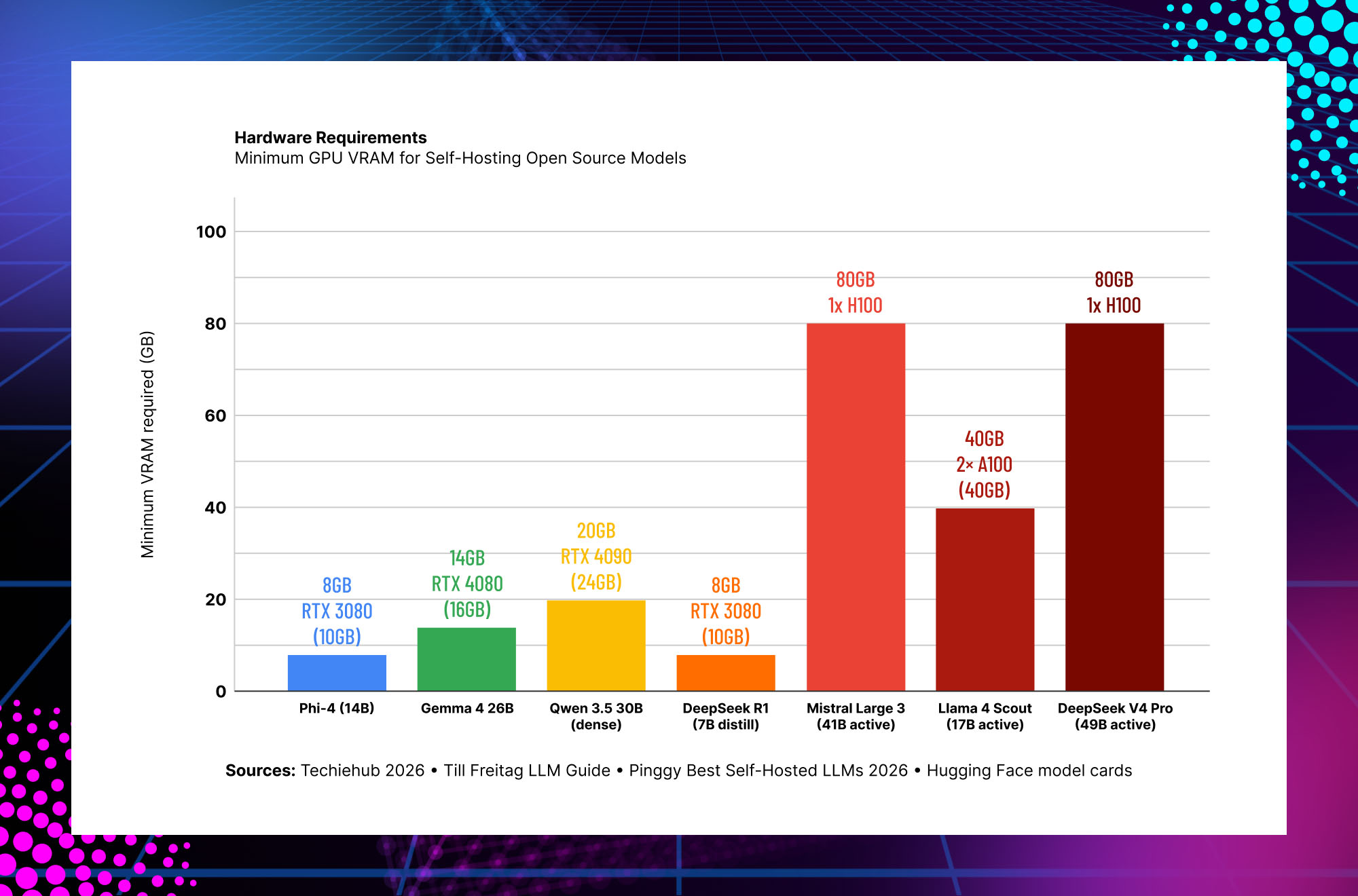
The good news for mid-market enterprises: the inference tooling has matured dramatically. Ollama, vLLM, and LM Studio now run 7B–14B models on a single consumer GPU with acceptable latency. For a team of 20 developers using an internal coding assistant based on a 14B model, an RTX 4090 server ($2,000–3,000 hardware cost) can serve the entire team. vLLM with PagedAttention is the production-grade serving solution for larger models, supporting Llama, Qwen, Mistral, DeepSeek, and most major architectures.
Quick decision rule: For models under 14B active parameters, a single consumer GPU (RTX 4080/4090) works for team-scale deployment. For 40B+ active parameters (Mistral Large 3, Llama 4 Maverick in full form), you need data center GPUs — at minimum one H100 or two A100s. For full MoE models at 685B+ (DeepSeek V4 Pro), most enterprises use quantized variants or third-party API hosting rather than full self-hosting.
Frequently Asked Questions
The Bottom Line: Open Source AI Is Ready for Enterprise. The Question Is Your Architecture.
The “open source AI models vs proprietary” debate is settled in 2026. The models are ready. The tooling is mature. The licensing options include genuinely permissive commercial terms. The benchmark gap has closed to rounding error on most tasks.
What is not settled — and what will determine which enterprises extract real value from open source AI versus which ones run over budget — is the deployment architecture. Which workloads go to self-hosted open models, which go to third-party hosted open models, and which go to proprietary APIs. How the data sovereignty risk of Chinese model APIs is managed. Which license your legal team has actually reviewed. Whether your token volume justifies self-hosting infrastructure or whether a third-party API is cheaper.
These are engineering and strategy questions, not technology questions. The technology is ready. The question is whether your organization has the capability to deploy it correctly.
At Trantor (trantorinc.com), we help enterprise organizations design and implement open source AI architectures that are technically sound, cost-efficient, and compliant with their specific regulatory requirements. From model selection and license review through infrastructure design, fine-tuning pipelines, and hybrid routing architectures — we have done this in production across healthcare, financial services, technology, and enterprise software organizations. If you are evaluating open source AI for the first time, scaling a pilot to production, or building the governance infrastructure to manage a mixed open source and proprietary AI portfolio — that is the work we are built for.











