Automation, zBlog
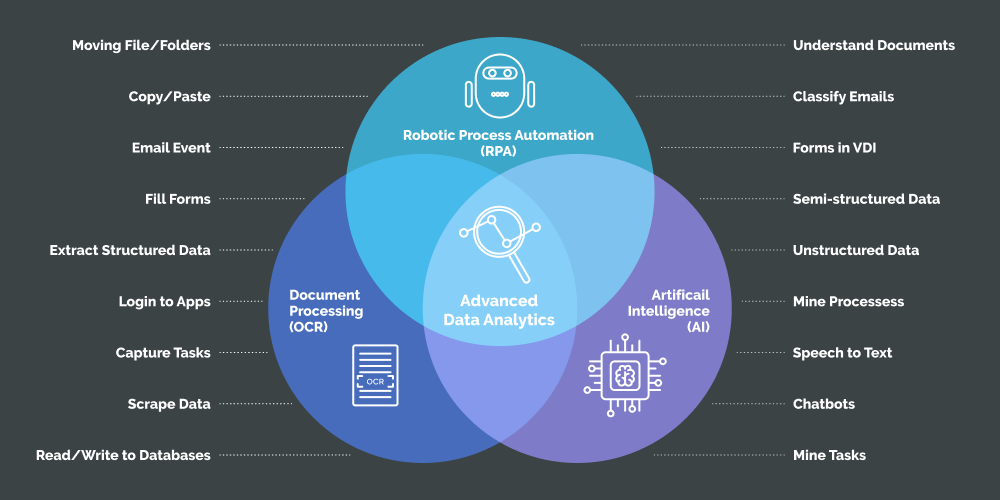
Empowering Enterprises through Intelligent Automation and Advanced Analytics
Sai Charan , Solution Architect | Updated: July 20, 2022
In the current industrial scenario, data is so precious that it is not wrong to say that it is the new oil. However, many organizations fail to capture the abundantly available data around them. Organizations across the globe employ tons of methods to capture data via lead magnets, downloadables, etc., and yet the potential of unstructured data that hides in plain sight is noticed by few.
Thousands of employees process multiple documents throughout the day, both online and offline. Unstructured data that hides in these documents carries huge potential for cost minimization, efficient management, and time saving.
With tools like Optical Character Recognition (OCR) that fit well within intelligent Robotic Process Automation (RPA), data from unstructured files can be efficiently extracted and put into structured formats, which is crucial for advanced data analytics.
The Abundance of Unstructured Data

Data is omnipresent in the form of text, audio files, videos, emails, hyperlinks, etc. Structured data (typically of textual nature) fits into a data model. It can be easily categorized, stored in databases, and operated. However, the hidden unstructured data from audio or video files, emails, or files like invoices, purchase orders, or payment advice need reliable and error-free extraction before it can be processed or analyzed.
Traditionally, unstructured data from files like invoices was manually extracted and fed into structured formats like Excel sheets. The process involved downloading invoices, reading them, and storing the relevant invoice data in the system. It entailed a lot of of time and cost for any organization.
Extracting Structured Data for Analytics
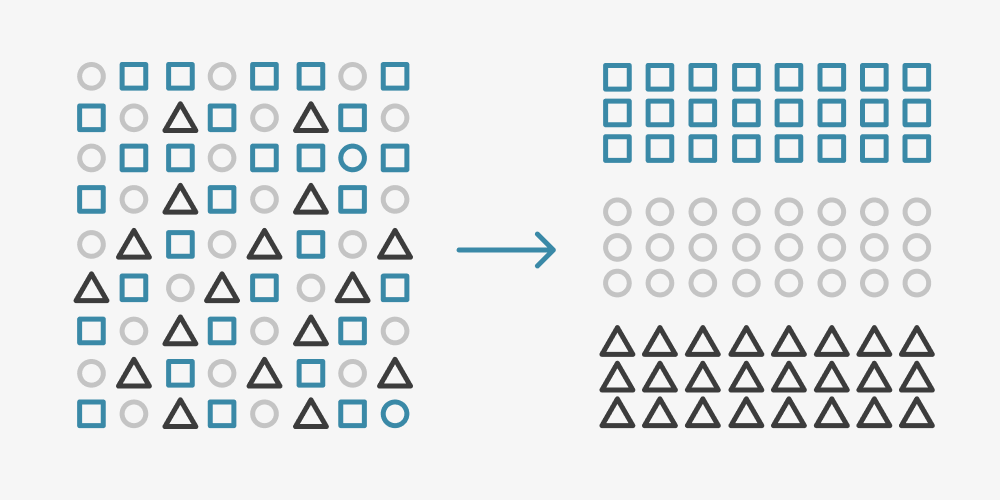
Data analytics need to work with structured data.
Intelligent RPA systems replace repetitive and manual work. These systems are complex, modular, and automate downloading invoices, extracting information, storing data, and adding functions as needed. Many RPAs also leverage deep learning algorithms to extract structured data from unstructured information and make the process smoother.
OCRs play a pivotal role since text extraction is crucial for RPA. Once a collection of different types of documents are uploaded to the system, OCR engines run on these specified lists of documents for text detection and digitization.
The extracted data must be error-free before it can be stored and analyzed. OCRs are not 100% accurate, so the extracted data undergoes human checks to ensure nearly zero errors.
Further, the advanced process of document understanding also uses OCR to digitize text from non-digital documents, making it a handy tool for organizations that also keep offline records.
It is pertinent to note that although people use OCR and document understanding interchangeably, they are not the same. OCRs do not have the context of the data they extract, nor do they understand it. Making sense of the extracted data or document understanding needs additional AI tools to form an intelligent RPA system.
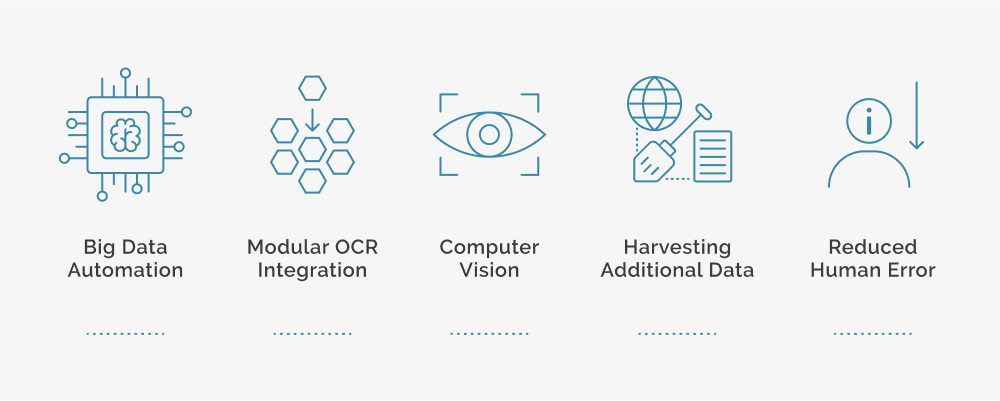
Advantages of OCR + RPA + AI
The benefits of moving to the cloud are many. The arguments listed below persuade businesses to migrate their assets to the cloud environment:
- Big Data Automation : Organizations process thousands of invoices and similar documents on a daily basis. RPAs with efficient OCRs reduce time and cost for these functions by automating repetitive tasks.
- Modular OCR integration : OCRs can be decoupled from the RPA systems. It means customers can choose to work with an OCR engine that delivers the best result for their use case and automate data entry functions.
- Computer Vision : Advanced AI applications like Computer Vision try to process elements on a computer screen instead of relying on metadata or object properties. Since Computer Vision can work only on digital data, it also relies on OCR for digitizing non-digital documents and uses fuzzy matching algorithms to detect text inconsistencies and improve the overall reliability.
- Harvesting additional data : RPA systems with OCR and advanced AI capabilities can use deep learning tools and find insights from big data bulk that will be missed by human cognition.
- Reduced human error : To err is human. Automating tedious tasks reduces the human error rate and uses human cognition to fix things where systems break, thereby making the entire system more effective.
Final Thoughts
Automating tedious and manual functions through RPAs is a practice that organizations need to adopt if they haven’t done so already. With added technical solutions like OCR and AI, organizations can extract error-free structured data from unstructured documents, store it efficiently, and analyze it in bulk. Implementing machine learning and insights from deep learning of data can help organizations function more efficiently, reduce costs, and improve the bottom line.










